这篇文章总结 Sundrani 等 2025 年发表在 Epilepsia 的研究:Deep learning on brief interictal intracranial recordings can accurately characterize seizure onset zones。它的问题非常临床:如果不等病人在 EMU 里自然发作,只拿 5 分钟静息 interictal SEEG/iEEG,能不能用深度学习判断哪些脑区属于 seizure onset zone?[1]
这篇文章和许多 seizure detection 论文不同。它不是检测某段信号是不是 ictal,而是用 interictal resting SEEG 直接做 SOZ 区域分类。作者使用 78 名 drug-resistant epilepsy 患者、超过 100 万个 interictal SEEG segment,训练一个多通道、多尺度、一维 CNN,并用 SHAP 看模型到底关注了哪些波形。
缩写表
| 缩写 | 全称 | 在这篇文章里的意思 |
|---|---|---|
| iEEG | intracranial electroencephalography | 颅内脑电总称,包含 SEEG 等形式。 |
| SEEG | stereo-electroencephalography | 立体定向脑电,本文主要数据来源。 |
| SOZ | seizure onset zone | 发作起始区,模型需要分类的目标区域。 |
| EMU | epilepsy monitoring unit | 癫痫监测病房,传统上需要等待自然发作。 |
| CNN | convolutional neural network | 卷积神经网络,用原始波形学习特征。 |
| DK atlas | Desikan-Killiany atlas | 解剖脑区 atlas,用于把 contact 分配到脑区。 |
| SHAP | Shapley Additive Explanation | 模型解释方法,用来估计输入时间点对预测的贡献。 |
| IED | interictal epileptiform discharge | 发作间期癫痫样放电,包括 spike、sharp transient 等。 |
| RNS | responsive neurostimulation | 反应性神经刺激,文中作为 outcome 分组之一。 |
| DBS | deep brain stimulation | 脑深部刺激,文中用于 outcome 判断。 |
| Youden index | sensitivity + specificity - 1 | 综合敏感性和特异性的指标。 |
论文想解决什么
传统 SEEG 术前评估经常需要住院数天到数周,等待自发或诱发发作。问题是:如果患者发作少、双侧发作、或者监测期间没有充分记录到关键发作,SOZ 判断会被拖慢。本文提出一个更激进的想法:只用 resting interictal SEEG,也就是发作间期、非 SPES、闭眼休息状态的短时数据,训练模型识别 SOZ。
作者的假设是:SOZ 不只在 ictal onset 时才有信息,interictal 信号里也可能包含区域特异的异常波形或低幅度形态。深度学习可以不预设特征,直接从原始波形里学习这些模式。
数据和预处理
这里最容易误解的是“采样到底采的是什么”。模型输入不是 seizure onset 附近的 ictal 片段,也不是刺激诱发数据。作者每名患者取的是 5 分钟 resting state SEEG,论文明确说明为 interictal、non-SPES。记录时患者清醒、闭眼,并被要求尽量不要睡着;这些片段距离 electroclinical activity 至少 4 小时。因此,模型真正学习的是短时 resting interictal iEEG 里有没有 SOZ-like signature,而不是直接学习发作开始时的演变模式。
原始信号经过 Butterworth filter,保留 1-59 Hz、61-119 Hz、121-150 Hz 三个频段,相当于避开 60 Hz 附近工频干扰。然后把信号切成 30 秒窗口,stride 为 18 秒。5 分钟是 300 秒,最后一个完整 30 秒窗口的起点是 270 秒;从 0 秒开始每隔 18 秒取一次起点,所以每名患者得到 16 个重叠窗口。
窗口起点可以这样理解:
| 窗口 | 起点 | 覆盖范围 |
|---|---|---|
| 1 | 0 秒 | 0-30 秒 |
| 2 | 18 秒 | 18-48 秒 |
| 3 | 36 秒 | 36-66 秒 |
| … | … | … |
| 16 | 270 秒 | 270-300 秒 |
这里的 stride 不是窗口长度,而是相邻窗口起点之间的距离。因此相邻 30 秒窗口会重叠 12 秒。
电极定位也不是模型自己猜的。患者的 SEEG contacts 来自临床植入;作者用术后 CT 和自定义 SEEG planning 软件 CRAVE 定位每一个 contact,再把每个 contact 分配到 Desikan-Killiany atlas 的一个解剖脑区。contact 位置还经过 staff engineer、attending neurosurgeon 和 attending epileptologist 核验。也就是说,模型输入的空间单位不是“随便抽 4 根电极”,而是“同一个 DK 解剖区域内的 4 个 contacts”。
SOZ 标签来自临床 ictal data 的判读,但训练输入仍然是 interictal resting data。具体做法是:如果某个 DK 脑区包含至少一个被癫痫专科医生判定参与一次或多次 ictal onset 的 contact,这个脑区就标为 SOZ;否则标为 non-SOZ。这个定义很重要,因为模型学的是“这个解剖区域是否属于 SOZ”,不是“这个 30 秒窗口里是否正在发作”。
模型整体流程
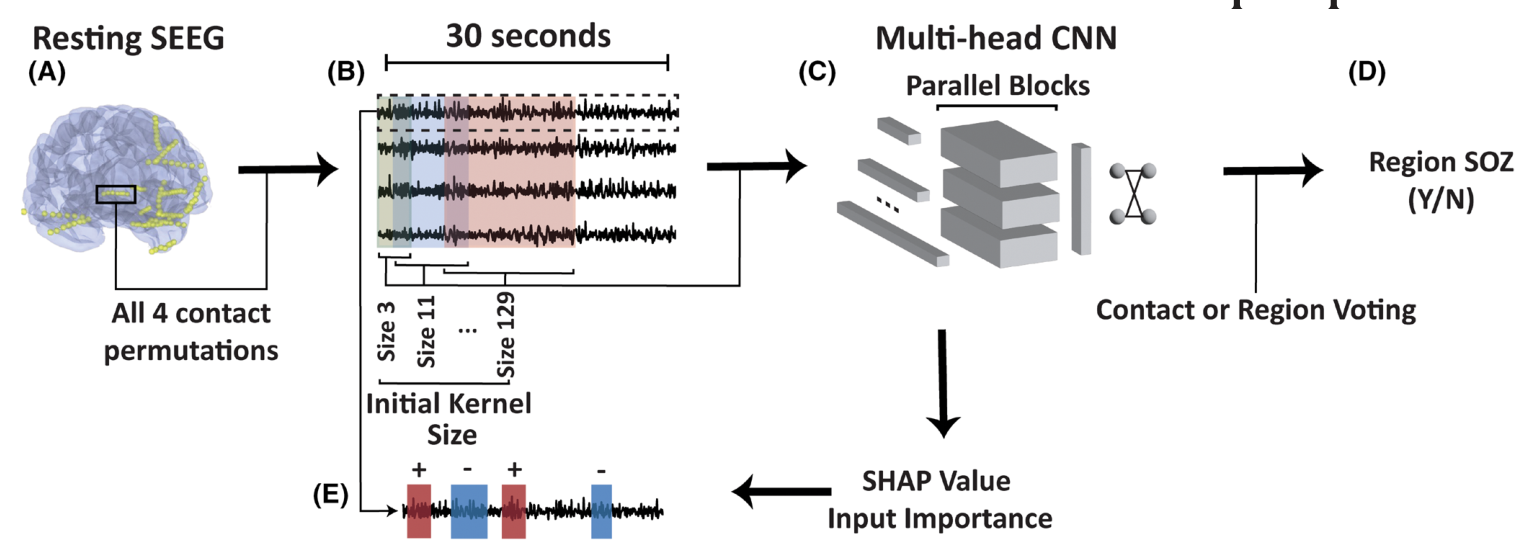
图 1 怎么读。 A-B:从 5 分钟 resting SEEG 中取 30 秒窗口,并从同一解剖区域里抽取 4 个 contact 的组合。C:输入进入 multi-head、multi-scale 的一维 CNN;不同 kernel size 对应不同时间尺度,可以同时看短暂尖波和较长时间模式。D:模型先输出 contact set 级预测,再通过 contact 或 region voting/aggregation 得到 anatomical region 是否属于 SOZ。E:训练后保存模型权重,并对表现最好的 fold 做 SHAP 分析。这里的“取最佳 fold 的权重”不是重新训练模型,而是加载那个 fold 已经训练完成、在 validation/test 表现最好的 CNN 参数,再问这个固定模型:输入里的哪些通道和时间点把 SOZ 分数推高或推低。
输入可以抽象成一个 4 通道、30 秒长的矩阵:
这里 $R$ 是一个解剖区域,4 是从该区域中抽取的 contact 数量,$T$ 是 30 秒窗口内的采样点数。模型输出该区域属于 SOZ 的概率:
这不是手工特征工程。作者没有先计算频带功率、连接矩阵或 spike rate,而是把预处理后的原始波形送进 CNN。整条路径可以拆成下面几个技术节点:
| 节点 | 输入 | 做了什么 | 输出 |
|---|---|---|---|
| 30 秒窗口 | 5 分钟 resting interictal SEEG | 以 30 秒窗口、18 秒 stride 切片 | 约 16 个时间窗口 |
| 4-contact set | 同一个 DK 脑区内的 contacts | 生成所有 4-contact permutations | 固定 4 通道输入 |
| multi-head 1D CNN | 4 通道、30 秒原始波形 | 多个并行卷积分支用不同 kernel size 扫描时间轴 | 多尺度波形特征 |
| 分类头 | 融合后的 CNN features | 输出 SOZ 概率 | 一个 contact set/window 的 SOZ score |
| aggregation | 同一 contact set 的多个窗口、同一脑区的多个 contact sets | confidence-weighted average | contact-set 级或 region 级 SOZ 判断 |
| SHAP | 已训练模型和输入波形 | 估计每个输入位置对 SOZ score 的正负贡献 | 红/蓝输入重要性 mask |
multi-head CNN 到底在做什么
图 1C 里的 multi-head CNN 可以理解成“几组并行的时间尺度滤波器”。输入不是单条 EEG,而是同一个解剖区域里 4 个 contact 的 30 秒波形;CNN 的一维卷积核沿时间轴滑动,同时保留 4 条通道之间的局部组合信息。所谓 multi-head,不是 Transformer 里的 self-attention head,而是多个并行卷积分支:每个 head 使用不同长度的一维卷积核,先从同一段输入里抽取不同时间尺度的模式,再把这些分支得到的特征合并起来做 SOZ / non-SOZ 分类。
图中标出的 initial kernel size 从 3、11 一直到 129。这里的 kernel size 指卷积核覆盖的时间采样点数量,不是手工指定的频段。短 kernel 更容易捕捉很短的 sharp transient、spike edge 或高频样活动;长 kernel 能覆盖更宽的 deflection、节律片段或低幅度持续形态。换句话说,模型不是预先规定“只找 spike”或“只算某个频带功率”,而是让不同尺度的卷积分支同时扫描原始波形,再由训练过程决定哪些尺度、哪些形态组合对 SOZ 标签最有用。
这也解释了为什么它被称为 multichannel、multiscale、one-dimensional CNN。multichannel 指输入有 4 个 contact;multiscale 指并行分支覆盖不同时间长度;one-dimensional 指卷积主要沿时间轴做,而不是把信号先变成二维时频图。论文主文没有展开每个 parallel block 的具体层数、通道数、dropout 或激活函数,所以这些不能从图 1 推断成确定超参数。能确定的是:输入是原始波形,特征提取由并行一维卷积分支完成,输出是区域 SOZ yes/no 的概率。
它的局限也在这里:模型一次只看一个区域内部的 4-contact 组合,不显式学习区域之间的传播网络或图结构,所以更像是在判断“这个区域内部有没有 SOZ-like interictal signature”,而不是重建完整 seizure network。
为什么要抽 4 个 contact
作者只纳入至少有 4 个 contacts 的 DK 脑区。对每个合格脑区,作者从该区域内部抽取所有 4-contact permutations,再把每一个 4-contact set 和每一个 30 秒窗口配对,形成模型训练样本。这样做后,每个样本的形状固定为“4 条 contact 通道 × 30 秒时间序列”,CNN 才能用同一套输入结构处理不同患者、不同脑区。
可以把生成样本的流程读成四步:
| 步骤 | 做了什么 | 目的 |
|---|---|---|
| 1 | 把每个 contact 定位到 DK 脑区 | 建立“contact 属于哪个解剖区域”的映射 |
| 2 | 只保留至少有 4 个 contacts 的脑区 | 保证每个输入都能凑出 4 条通道 |
| 3 | 在同一脑区内抽取所有 4-contact permutations | 让模型看到该区域内部不同 contact 组合的波形 |
| 4 | 每个 4-contact set 配上 16 个 30 秒 interictal 窗口 | 扩大样本数,并覆盖 5 分钟内的时间变化 |
这也是为什么论文能得到超过 100 万个 processed windows:样本数不是只有“78 名患者 × 16 个窗口”,而是还乘上了每个患者、每个 DK 区域内大量 4-contact permutations。
但这个设计也带来限制:模型判断的是 sampled contact set 或 region,不是单个 contact 的精确病理状态。contact-set 级预测会先在 5 分钟内做 confidence-weighted average,区域级预测再对同一 DK 脑区内的多个 contact sets 做 confidence-weighted average。因此最后报告的更接近“这个脑区整体是否 SOZ-like”,而不是“某一个 contact 一定是病灶核心”。
训练到底怎么做
这不是把 SOZ 和 non-SOZ 各取很多段“30 分钟”数据,再做逻辑回归。每个患者只有 5 分钟 resting interictal SEEG;切出来的是 30 秒窗口。真正的训练样本可以理解成下面这个单位:
| 训练样本字段 | 含义 |
|---|---|
| 患者 | 来自 78 名 drug-resistant epilepsy 患者之一 |
| 解剖区域 | 一个 DK atlas 脑区 |
| contact set | 该脑区内部的一个 4-contact permutation |
| 时间窗口 | 5 分钟 resting interictal SEEG 中的一个 30 秒窗口 |
| 输入 | 4 条 contact 通道的原始波形 |
| 标签 | 该 DK 脑区是否包含 ictal onset contact |
所以,一个正样本不是“某一段 30 秒里正在发作”,而是“这个 30 秒 interictal 波形来自一个被临床判定为 SOZ 的 DK 脑区”。一个负样本则是来自 non-SOZ DK 脑区的 30 秒 interictal 波形。标签挂在区域上,再继承给该区域内的 4-contact set 和 30 秒窗口。
模型训练方式是 supervised deep learning。CNN 接收 4 通道、30 秒波形,多个 convolution heads 自动学习不同时间尺度的波形模式,最后输出该输入属于 SOZ 区域的概率。训练时用 weighted binary cross-entropy 比较预测概率和 SOZ/non-SOZ 标签,再用 Adam optimizer with weight decay 更新 CNN 的所有参数。论文还提到训练在 3 个 epoch 后停止,并在每个 fold 的 validation set 上选择表现最好的 epoch。
数据划分也不是把同一个患者的数据混在训练和测试里。作者做 five-fold assessment:每个 fold 约 65% 患者用于 training,15% 用于 validation,20% 作为 held-out test;同一患者不会同时出现在 train、validation、test 中。作者还强调同一 contact 的所有时间窗口只进入一个 split,以减少同源窗口泄漏。
训练和测试的单位可以再拆细一点:
| 阶段 | 具体做法 | 为什么重要 |
|---|---|---|
| 样本生成 | 每个 DK 脑区内的 4-contact set 乘以 16 个 30 秒窗口 | 产生超过 100 万个 processed windows |
| 标签继承 | 同一 DK 脑区内的所有 4-contact/window 样本继承区域 SOZ 标签 | 输入是 interictal,标签来自 ictal onset 判读 |
| 类别平衡 | loss 使用 SOZ/non-SOZ 权重 | 避免 non-SOZ 多数类压倒 SOZ 少数类 |
| 优化 | Adam optimizer with weight decay | 更新 CNN 卷积核和分类层参数 |
| 早停/选择 | 训练 3 个 epoch,取 validation 表现最好的 epoch | 防止只报告训练集效果 |
| 对照 | 做 random SOZ label permutation control | 检查模型是否真的学到标签相关信息 |
逻辑回归的直觉可以用来理解最后一步“输出一个概率”,但不能把这篇方法叫逻辑回归。逻辑回归通常是先手工得到一个特征向量,再学一个线性分类边界;这篇文章是把预处理后的原始波形直接送进 multichannel、multiscale 1D CNN,让卷积层自己学习 spike、sharp transient、large deflection 或低幅度形态等有用模式。
推理和 aggregation 怎么做
训练时每个 30 秒窗口、每个 4-contact set 都能得到一个 SOZ 概率,但临床上真正关心的是 contact set 或解剖区域。因此作者没有只看单个窗口,而是做两级汇总。
第一,contact-set 级结果:对同一组 4 contacts 在整个 5 分钟内的多个 30 秒窗口预测做 confidence-weighted average,得到这一组 contact set 的 SOZ 判断。第二,region 级结果:对同一 DK 脑区内所有 4-contact sets 的预测再做 confidence-weighted average,得到这个解剖脑区是否 SOZ 的判断。
这里的 confidence-weighted average 可以理解成“更有把握的预测权重更高”。但论文主文没有给出 confidence 的精确定义或公式,所以不能把它写成某个固定数学表达。重要的是读懂层级:窗口预测不是最终终点,最终结果来自 5 分钟内的时间汇总和同一脑区内的 contact-set 汇总。
损失函数和评价指标
论文提到模型使用 weighted binary cross-entropy。可以写成:
$y=1$ 表示 SOZ,$y=0$ 表示 non-SOZ。$w_1$ 和 $w_0$ 用来处理类别不平衡。SOZ 区域通常比 non-SOZ 少,如果不用权重,模型可能倾向于预测多数类。
文章报告 sensitivity、specificity、accuracy 和 Youden index。Youden index 很适合看模型有没有同时兼顾敏感性和特异性:
$J=0$ 接近随机,$J=1$ 表示敏感性和特异性都达到 1。
整体性能
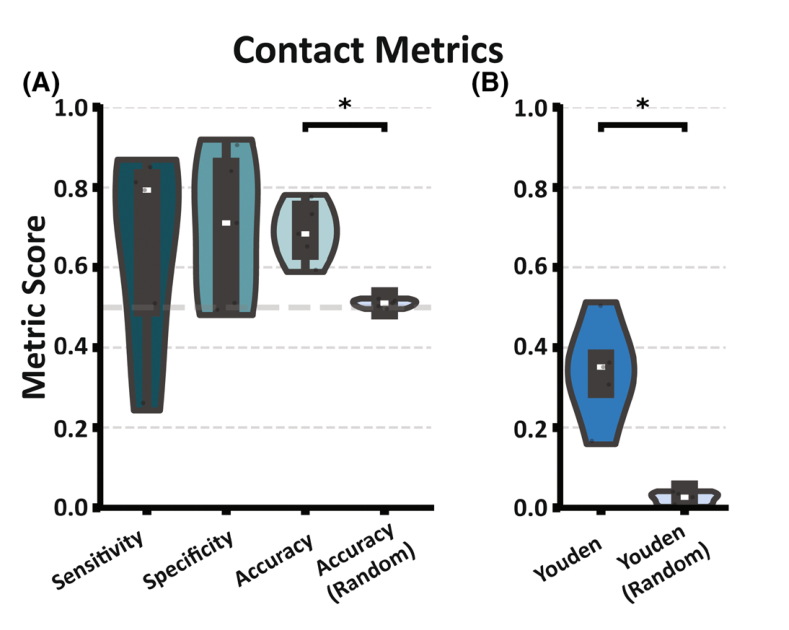
图 2 怎么读。 A 展示 contact-aggregated sensitivity、specificity、accuracy,并和随机标签模型比较。B 展示 Youden index,也和随机标签比较。模型在 held-out test set 上明显优于随机标签:locationwise sensitivity 为 0.702,specificity 为 0.741,accuracy 为 0.738;contactwise aggregation 的 sensitivity 为 0.646,specificity 为 0.693,accuracy 为 0.688。这个结果说明 interictal resting SEEG 中确实存在可被模型利用的 SOZ 相关信息。
这里要注意,“优于随机”不等于“可以直接替代临床判断”。0.738 的区域级 accuracy 说明模型有辅助价值,但还远没到独立决定手术靶区的程度。
脑区表现和 outcome 分层
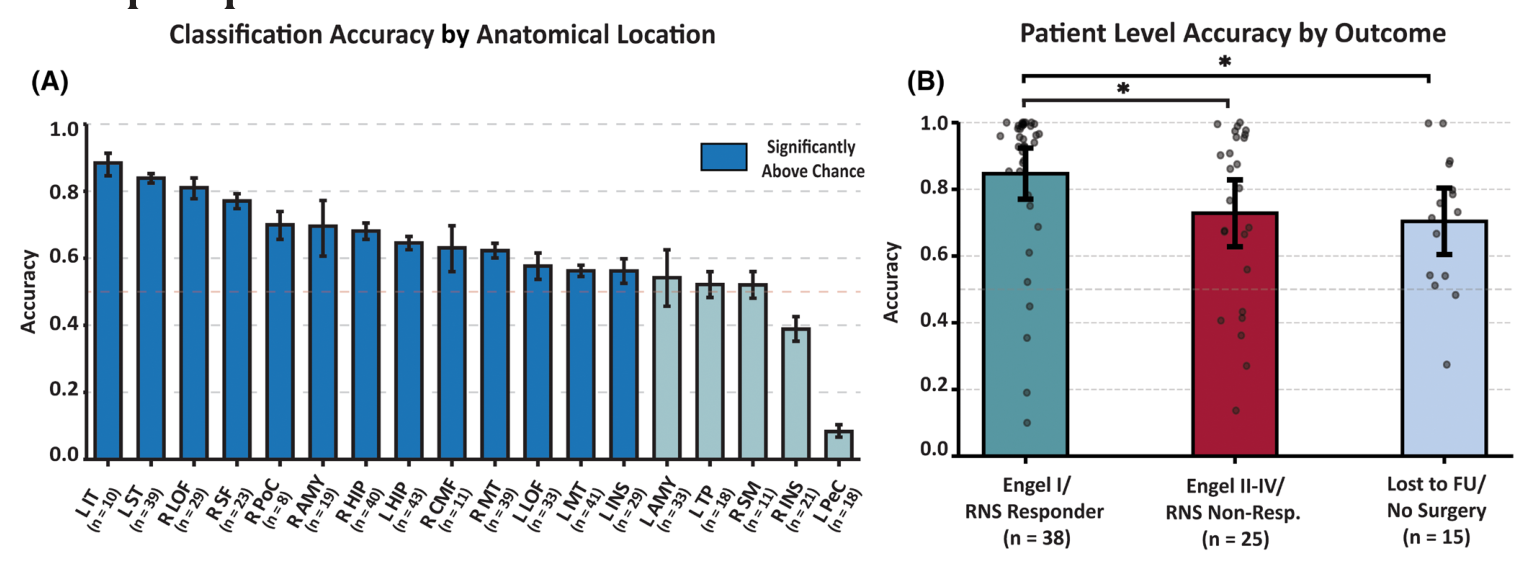
图 3 怎么读。 A 按 DK 脑区统计分类准确率。18 个样本足够的区域里,13 个区域显著高于 chance。表现最好的区域包括左下颞回、左上颞回、右外侧眶额回、右上额回和右中央后回;表现较差的区域包括左杏仁核、左颞极、右缘上回、右岛叶和左中央前回。B 按 1 年 outcome 分组:Engel I 或 RNS responder 的患者准确率最高,Engel II-IV/RNS nonresponder 次之,未手术或随访不足者更低。
这个 outcome 分层很重要。模型训练标签来自临床 SOZ 判断,而 favorable outcome 可以看成标签更可信的间接证据。如果手术或刺激效果不好,可能说明原始 SOZ 标签就不够准确或病灶更弥散,模型性能自然会被影响。
SHAP:模型到底看到了什么波形
SHAP 的作用不是再训练一个新分类器,而是在模型已经训练好以后解释它为什么给出某个预测。本文 Methods 2.4 交代得比较具体:作者在一个已经训练好的 fold 上使用 SHAP 的 GradientExplainer,从 training data 里取 1000 个 background examples,然后对 test data 中选出的示例计算 SHAP values。Figure 1E 里说的 highest performing fold,就是加载这个表现最好的 fold 的 CNN 权重,用固定后的模型做解释。
这一步可以按下面的顺序理解:
| 步骤 | 论文中的做法 | 这一步回答什么问题 |
|---|---|---|
| 1 | 先完成 five-fold CNN 训练,并保存每个 fold 的模型权重 | 先得到真正用于 SOZ 分类的模型 |
| 2 | 选取表现最好的 fold,加载该 fold 的 CNN 权重 | 解释对象是一个固定 CNN,不是重新训练 |
| 3 | 从 training data 里取 1000 个 background examples | 给 SHAP 一个参考分布:模型在“背景输入”上通常会怎样输出 |
| 4 | 用 GradientExplainer 解释 selected test examples |
对测试样本中的每个输入位置估计贡献 |
| 5 | 得到 raw positive 和 raw negative SHAP values | 区分哪些位置推高 SOZ score,哪些位置推低 SOZ score |
| 6 | 正负 SHAP values 分别做 histogram equalization,缩放到可视化范围 | 让热图颜色能覆盖从弱贡献到强贡献的范围 |
为什么需要 background examples?因为 SHAP 不是只看某个波形点的绝对电压,而是问:相对 training data 提供的背景参考,这个 test input 里的某个位置让模型输出改变了多少。对本文的输入来说,一个输入位置大致对应 4-contact、30 秒矩阵里的某个 contact 和某个时间点附近的波形信息。模型输出可以近似拆成:
这里 $f(x)$ 是 CNN 对当前 4-contact、30 秒输入给出的 SOZ score,$E[f(x_{\mathrm{background}})]$ 是 1000 个 training background examples 上的参考输出,$\phi_k$ 是第 $k$ 个输入位置对当前预测的贡献。$\phi_k > 0$ 表示这个位置把模型输出往 SOZ 方向推;$\phi_k < 0$ 表示这个位置把模型输出往 non-SOZ 方向推。
所以你的理解可以作为直觉,但要稍微改一下:SHAP 不是把某一个采样点从 30 秒信号里物理删除,因为删除会改变输入长度,CNN 就不能接收同样形状的输入。更准确地说,它问的是:如果这个位置不带有当前 test waveform 的取值,而是由 training background/reference 来代表,那么模型输出会怎样变化?如果当前位置的真实波形相对 background 让 SOZ score 变高,它就是正 SHAP;如果让 SOZ score 变低,它就是负 SHAP。
传统 Shapley value 会考虑“某个特征加入不同特征组合前后,输出平均改变多少”,所以直觉上像反复遮挡、替换、加入特征后看分数升降。但本文用的是 GradientExplainer,它不是逐点暴力枚举所有删点组合,而是利用 CNN 的梯度,在 1000 个 training background examples 作为参考的条件下近似估计每个 contact/time 位置的边际贡献。
GradientExplainer 的意义是:CNN 是可微模型,可以用梯度信息近似估计这些输入位置对输出的贡献,而不是把 4 通道乘以所有时间点的组合逐个枚举遮挡。论文没有公开更细的实现参数,比如 background examples 如何抽样、解释的是 logit 还是 probability、是否对时间点做额外平滑,所以博客不能把这些细节写死。
Figure 4 里的红/蓝 mask 就来自这组 SHAP values:红色是 positive SOZ contribution,蓝色是 negative SOZ contribution。raw positive 和 raw negative SHAP values 会分别经过 histogram equalization 再显示,所以颜色深浅主要用于看同一张图里的相对贡献强弱,不应该直接当作概率大小。
因此,图题里的 SHAP: +67.9% / -32.1% 不应该读成模型概率,也不是准确率。它是这个示例中正向/负向 SHAP 贡献的方向性总结:更多红色说明该输入里有较多片段把模型推向 SOZ;蓝色则表示有些片段把模型推向 non-SOZ。
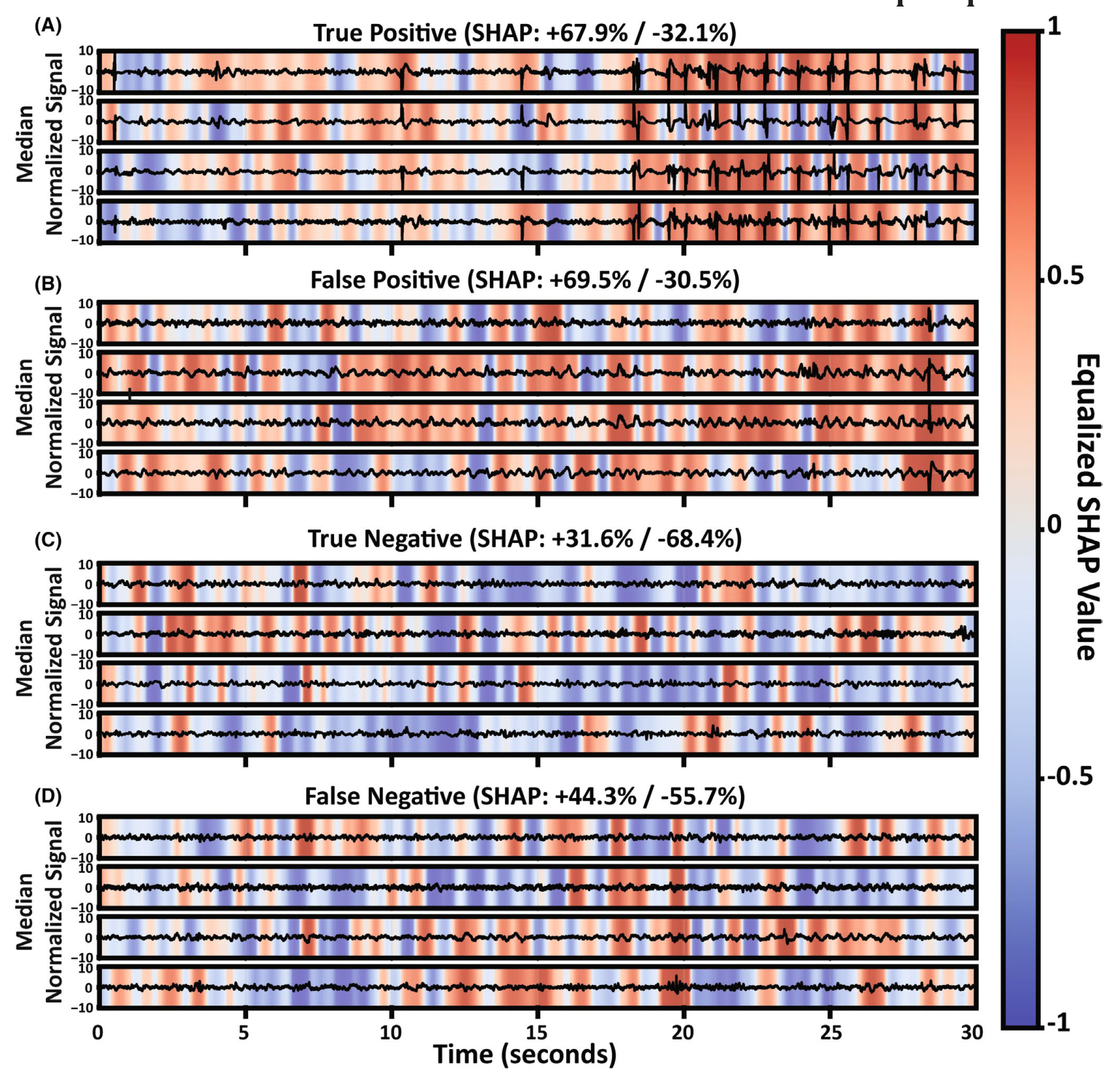
图 4 怎么读。 A 是 true positive:模型预测 SOZ,临床标签也是 SOZ。红色 SHAP 集中在 spike、HFO-like activity 和 large deflection 附近。B 是 false positive:模型预测 SOZ,但标签是 non-SOZ;这些片段也有类似 sharp transient,因此可能“像 SOZ”。C 是 true negative:信号更平滑、低幅度,蓝色贡献更多。D 是 false negative:SOZ 区域没有明显大幅异常,模型可能漏掉更微弱或更复杂的异常形态。
这张图的意义在于,模型并不是完全不可解释。它确实关注了临床熟悉的 IED 形态,但也可能被 non-SOZ 区域的尖锐瞬变误导。需要注意的是,SHAP 是模型 attribution,不是因果证明。红色区域不是说“这个时间点就是 SOZ”,而是说“对这个 CNN 来说,这里的波形让 SOZ score 升高”。同理,蓝色区域也不是临床上的“保护性区域”,只是该模型在该输入上的负向证据。
中位数归一化和直方图均衡化
作者还比较了 median/IQR normalization 和 histogram equalization 两种输入归一化策略。前者更保留原始幅度形态,所以大 spike 和大 deflection 更突出;后者会弱化幅度差异,让低幅度形态也有机会被模型关注。
这一步不是只把同一张图换一种颜色显示,而是重新训练并评价 histogram-equalized input data 的模型,然后再做 SHAP 对比。论文这样做是为了回答一个关键问题:模型是不是只会盯着大幅 spike?如果 median-normalized 模型的 SHAP 总是集中在大幅 spike 和 large deflection 上,那可能只是幅度主导;histogram equalization 则能测试低幅度波形在被凸显后是否也能支持 SOZ 分类。
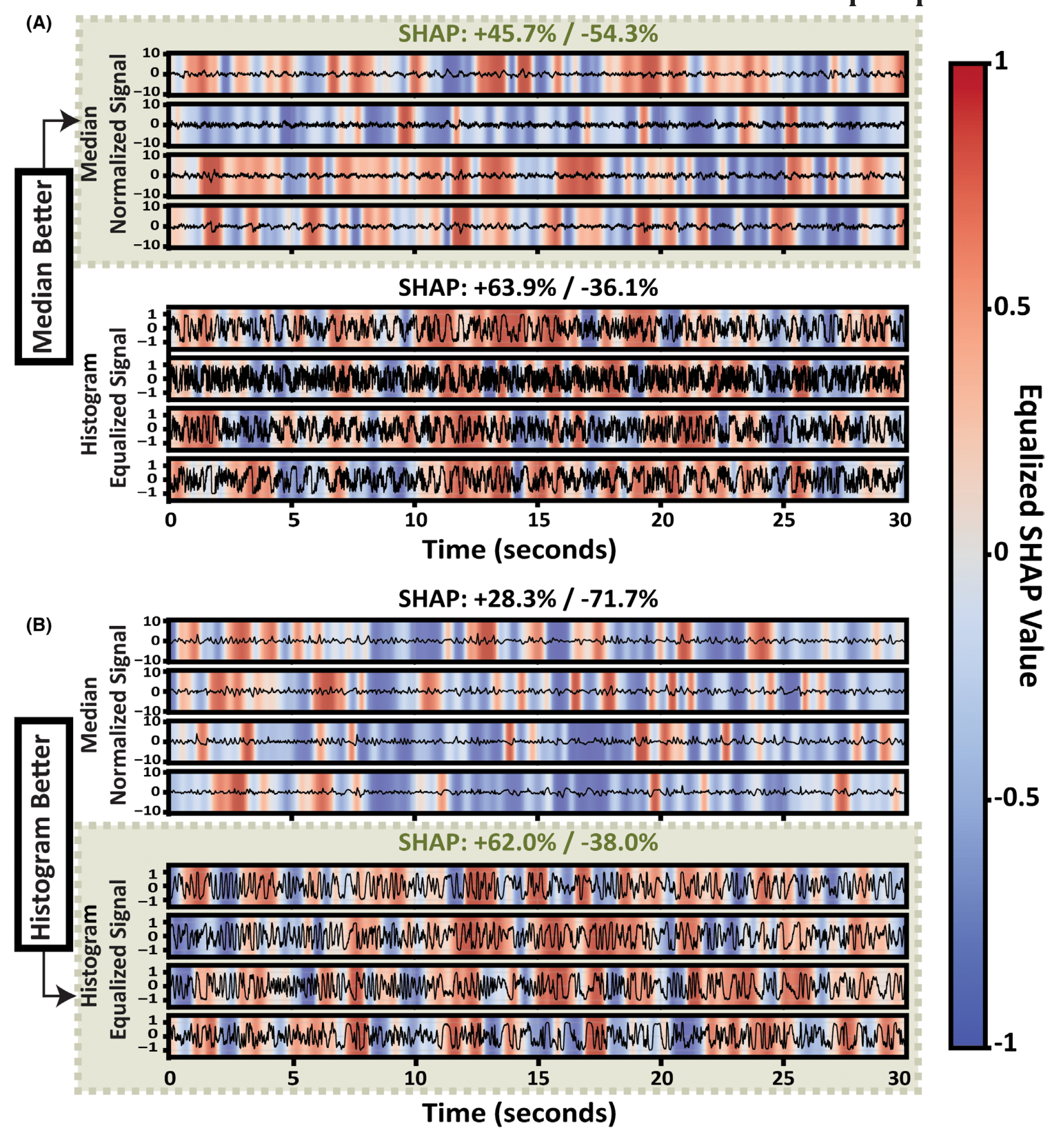
图 5 怎么读。 A 是 median normalization 表现更好的例子。大幅异常波形对模型判断贡献明显,histogram equalization 反而可能过度强调低幅度 deflection,导致错误倾向。B 是 histogram equalization 表现更好的例子。这里 median normalization 可能忽略了一些低幅度但有意义的 epileptiform morphology,而 histogram equalization 把这些信息凸显出来。
作者专门挑选了两种归一化模型输出差异最大的样本来展示。Figure 5A 是 median normalization 正确、histogram equalization 错误的 true negative:histogram equalization 可能过度放大低幅度 deflection,让模型误判为 SOZ。Figure 5B 则相反:histogram equalization 捕捉到一些 median normalization 没有凸显的低幅度 epileptiform morphology,因此把它们赋予正向 SOZ SHAP。
这个结果很有启发:SOZ 相关信息不一定都是“肉眼很大的 spike”。一些低幅度、形态 subtle 的波形也可能有价值。后续如果做自动 IED 或 SOZ 模型,不能只把大幅尖波当作唯一目标。
这篇文章的强点
第一,问题设置很有临床意义。它直接挑战“必须记录到发作才能定位 SOZ”的传统依赖,尝试用短时 interictal resting data 做区域级判断。
第二,输入是 feature-agnostic 的原始波形。相比手工计算 spike rate、频带能量、功能连接,它给了模型发现未知形态的空间。
第三,SHAP 分析没有停留在漂亮热图,而是联系到 true positive、false positive、true negative、false negative,并进一步比较归一化策略对波形解释的影响。
需要谨慎的地方
第一,这是单中心 78 名患者数据。不同中心的采样率、滤波、参考方式、电极规划和标注习惯都可能影响泛化。
第二,SOZ 标签不是绝对真值。文章也承认 outcome 分析提示 label accuracy 会影响模型表现。深度学习模型再强,也会被不稳定标签拖累。
第三,模型一次只看一个区域的 4-contact 组合,没有显式建模跨区域传播网络。因此它更像“区域是否有 SOZ-like interictal signature”的分类器,而不是完整 seizure network 模型。
第四,5 分钟可能不足以覆盖所有 interictal variability。对于 spike 稀少、睡眠状态依赖明显或发作网络复杂的患者,更长时间或不同状态的数据可能必要。
第五,论文只评估了一个 model architecture,主文也没有给出每个 CNN block 的完整层数、隐藏通道数等实现细节。因此读者可以清楚理解模型路线和关键节点,但如果要完全复现实验,还需要代码或补充实现信息。
一句话总结
这篇文章可以理解为:用 5 分钟 resting interictal SEEG,按 DK 解剖区域定位 contacts,生成区域内部 4-contact、30 秒窗口样本,训练多通道、多尺度 1D CNN 判断区域是否属于 SOZ,再通过 confidence-weighted aggregation 得到 contact-set/region 级结果,并用 SHAP 解释模型关注的 IED、大幅 deflection 和低幅度形态。它在 benchmark 里的位置很清楚:代表“不依赖 ictal seizure 捕获、直接从 interictal 原始波形学习 SOZ signature”的路线。
参考文献
[1] Sundrani S, Johnson GW, Doss DJ, Makhoul GS, Monroy Lerma BH, Reda A, Cavender AC, Liao E, Rogers BP, Williams Roberson S, Bick SK, Morgan VL, Englot DJ. Deep learning on brief interictal intracranial recordings can accurately characterize seizure onset zones. Epilepsia. 2025;66:3180-3192. doi: 10.1111/epi.18478.