Spiking Neural Networks and Their Applications: A Review 详解
来源:Yamazaki, K.; Vo-Ho, V.-K.; Bulsara, D.; Le, N. Spiking Neural Networks and Their Applications: A Review. Brain Sciences 2022, 12(7), 863. DOI: https://doi.org/10.3390/brainsci12070863
这篇综述的目标很明确:把 spiking neural networks, SNNs 从生物神经元基础、脉冲神经元模型、突触模型、学习规则、编码方式、软件框架,到计算机视觉和机器人应用串起来。它不是提出新算法的论文,而是一篇“入门到应用”的综述。真正值得读的地方在于:它把 SNN 和传统 ANN 的差别放在公式层面讲清楚。
一句话概括:
ANN 主要用连续实数激活值传播信息;SNN 用离散 spike 和连续时间动力学传播信息,因此更接近生物神经系统,也更适合事件驱动、低功耗、时序信号和神经形态硬件。
1. 这篇论文的主线
论文可以分成七层:
- 为什么需要 SNN:ANN 很强,但计算和能耗高;SNN 用稀疏 spike 表达信息,理论上更省能。
- 生物神经元基础:膜电位、动作电位、突触传递。
- ANN 回顾:ANN 用 firing rate 或连续激活值表示神经元活动。
- SNN 神经元模型:HH、LIF、Izhikevich、AdEx。
- 突触模型:单指数、双指数、突触电流。
- SNN 学习机制:spike backpropagation、STDP、R-STDP、PES、intrinsic plasticity、ANN-to-SNN conversion。
- 应用:计算机视觉、事件相机、机器人、SLAM、导航和神经形态系统。
2. 图表怎么读
Figure 1 展示生物神经元结构:dendrite 接收输入,soma 积分膜电位,axon 传导动作电位,synapse 负责神经元之间的信息传递。理解 SNN 时,dendrite/soma/axon/synapse 可以分别对应输入整合、状态更新、spike 输出和连接权重。
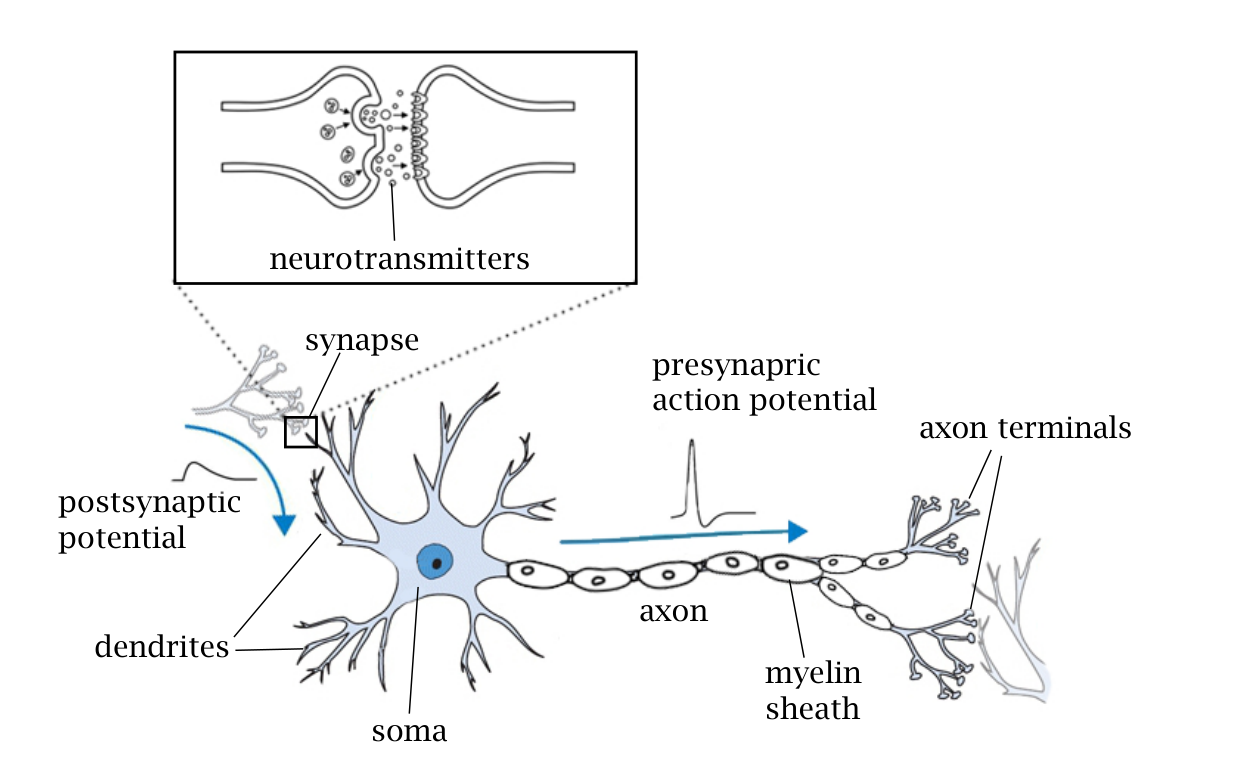
图 1. Yamazaki 等 2022 原文 Figure 1,展示生物神经元、轴突、树突、髓鞘、突触和 neurotransmitter 释放位置。原文为 CC BY 4.0 开放获取。
Figure 2 对比 biological neuron、ANN neuron 和 SNN neuron。ANN 的输出是连续标量;SNN 的输出是 spike 序列。这个图的重点不是“形状像不像神经元”,而是信息表达方式不同:ANN 是数值幅度编码,SNN 是事件时间编码。
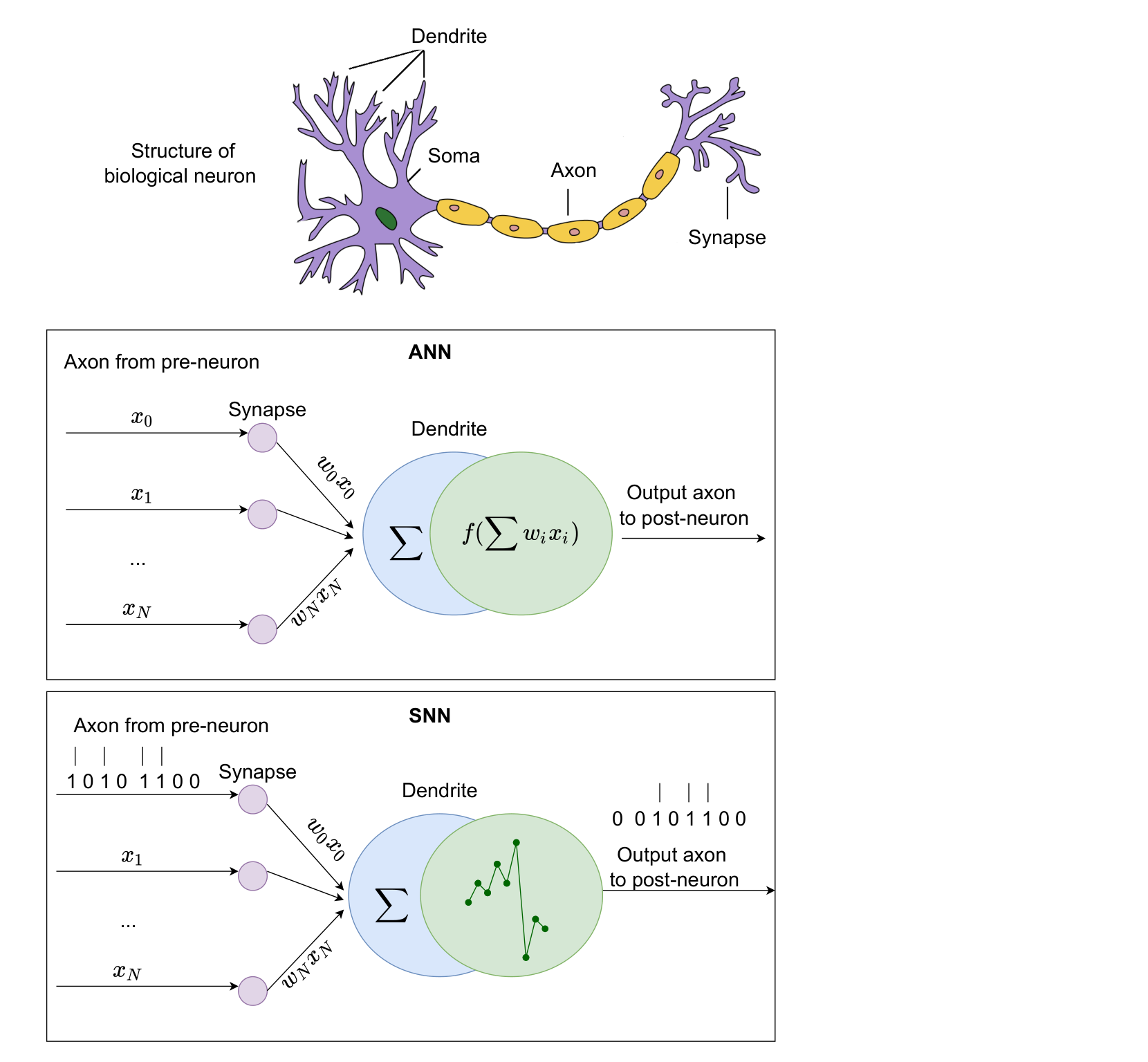
图 2. Yamazaki 等 2022 原文 Figure 2,对比 biological neuron、ANN neuron 和 SNN neuron 的输入、突触权重、树突整合与输出形式。原文为 CC BY 4.0 开放获取。
Figure 3 对比不同 spiking neuron models 的生物真实性和实现成本。HH 最生物真实但最重;LIF 最简单、最适合大规模模拟;Izhikevich 和 AdEx 介于二者之间。
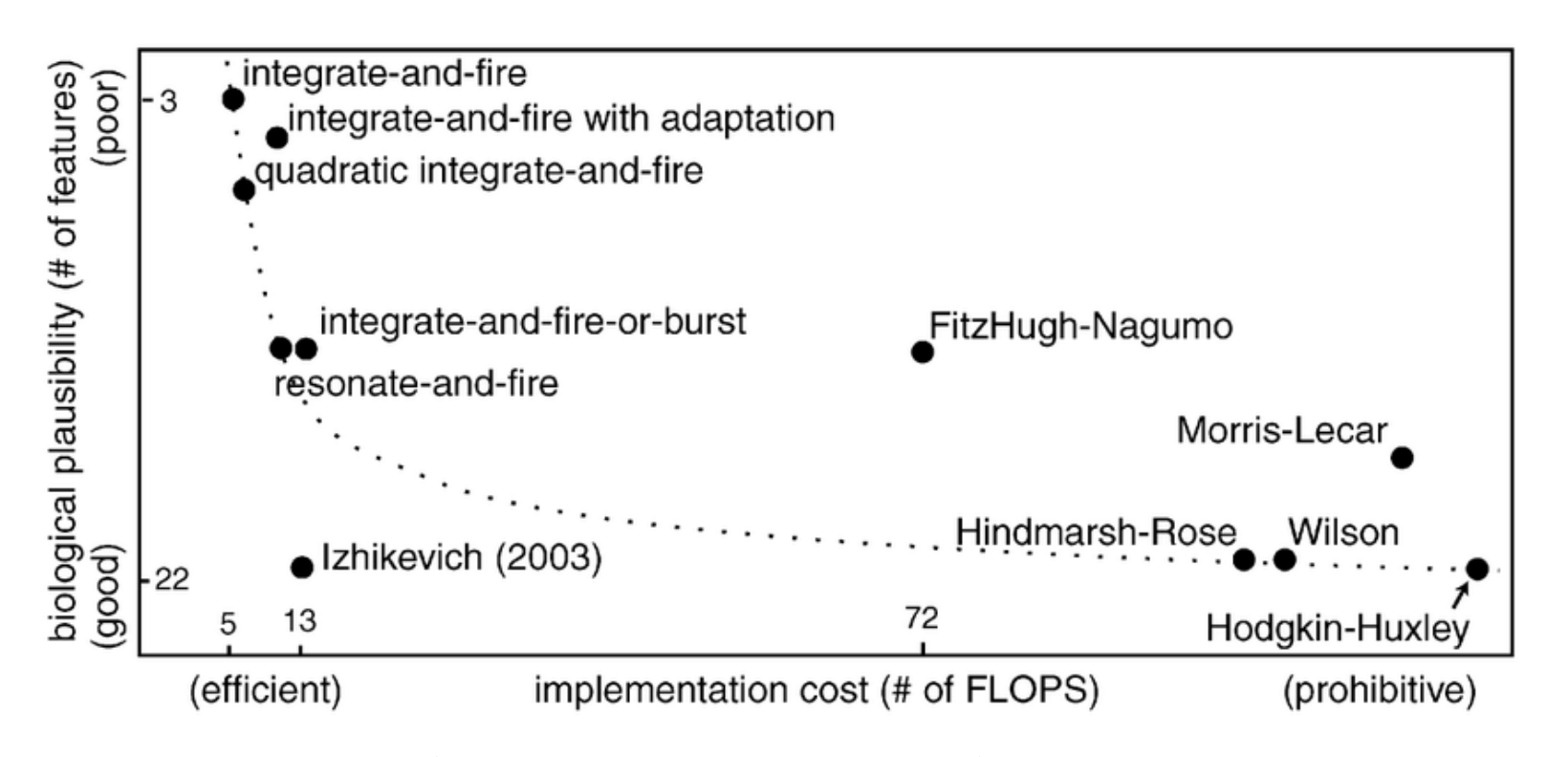
图 3. Yamazaki 等 2022 原文 Figure 3,用 biological plausibility 和 implementation cost 对不同 spiking neuron models 做二维比较。原文为 CC BY 4.0 开放获取。
Figure 4 解释 STDP:pre-synaptic spike 和 post-synaptic spike 的先后顺序决定突触增强还是减弱。pre 早于 post 通常对应 LTP;post 早于 pre 通常对应 LTD。
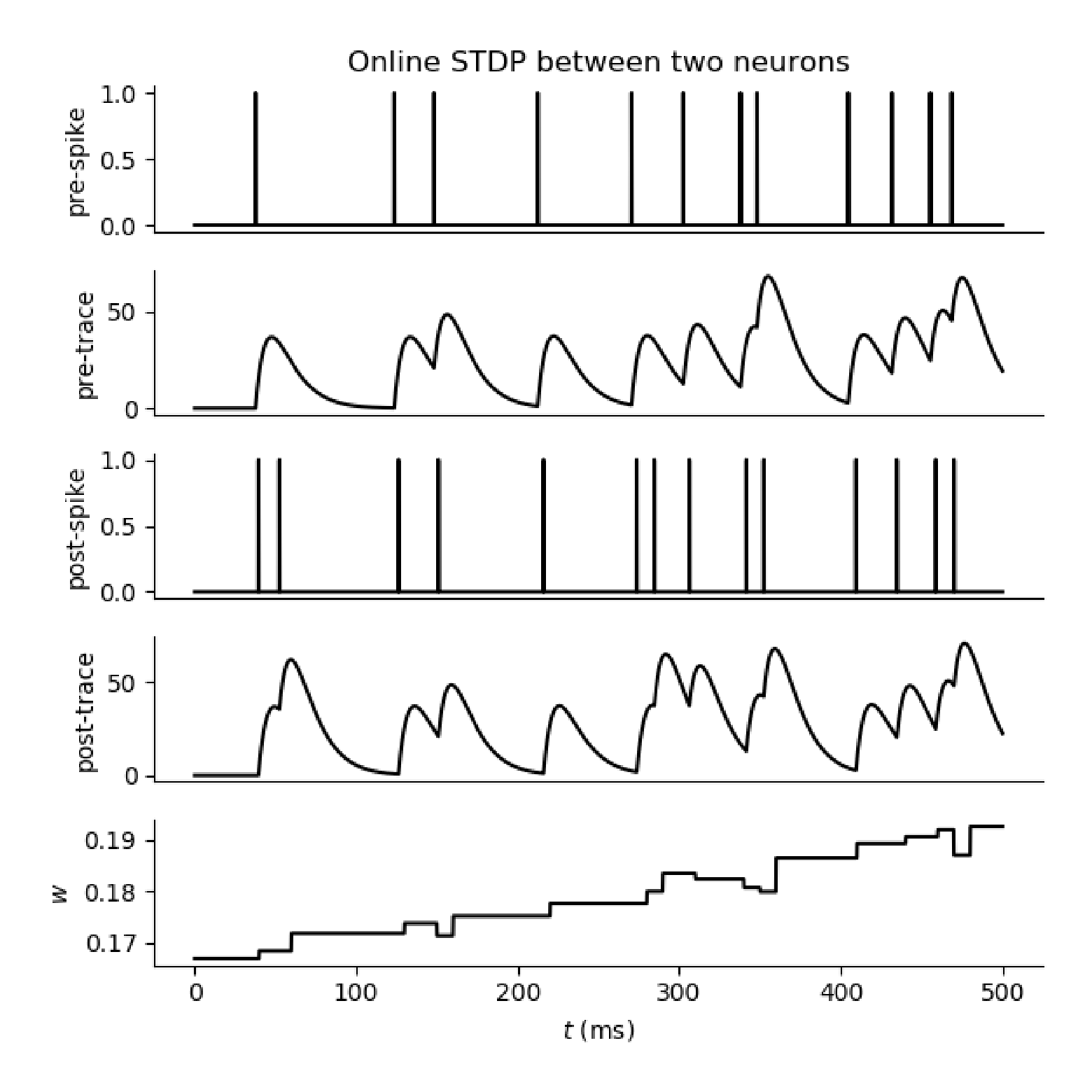
图 4. Yamazaki 等 2022 原文 Figure 4,展示 pre-spike、post-spike、trace 变量和突触权重在在线 STDP 过程中的变化。原文为 CC BY 4.0 开放获取。
Figure 5 是 DCSNN 的 digit recognition 结构。它说明 SNN 可以做类似 CNN 的层级视觉处理,但训练常依赖 STDP、R-STDP 或 ANN-to-SNN conversion。
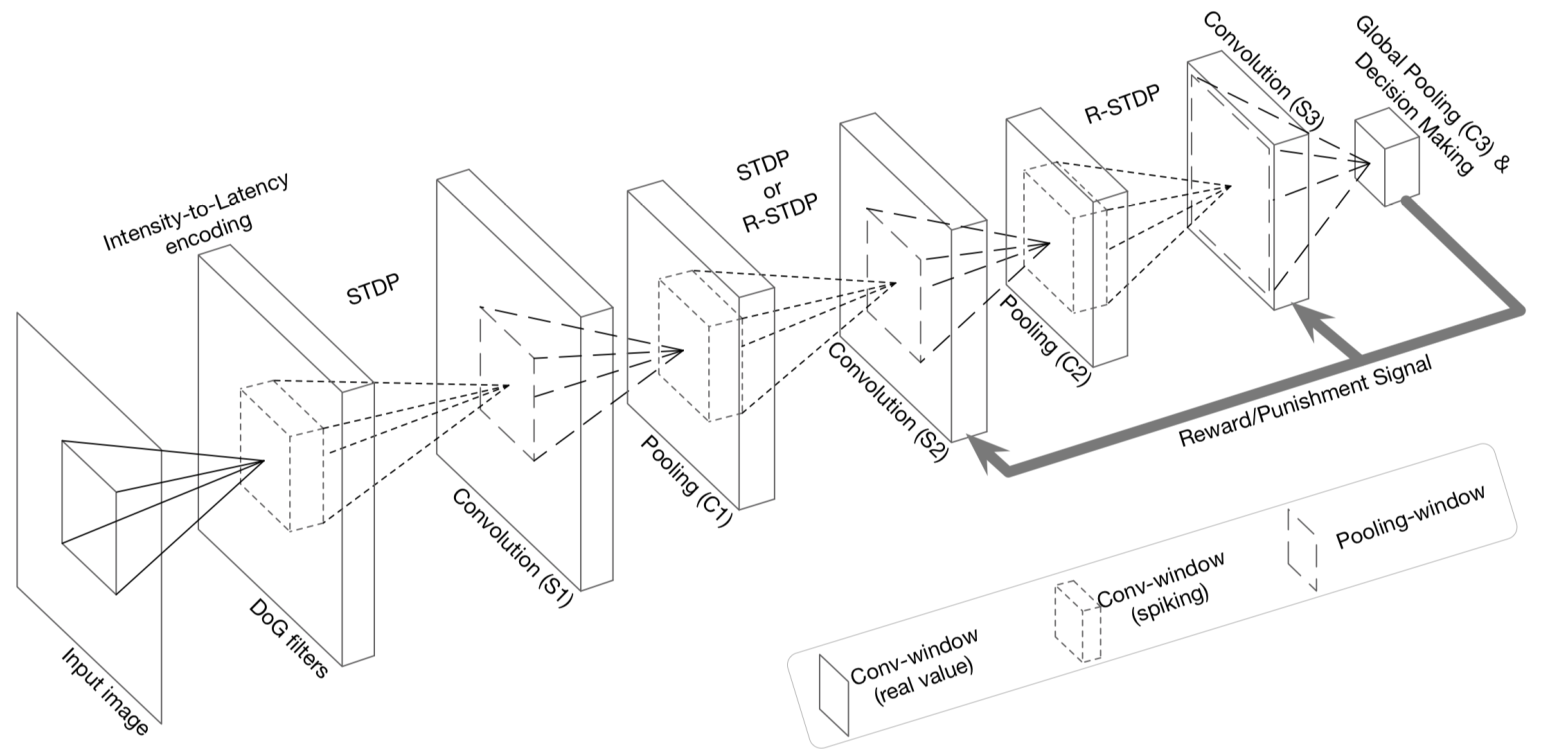
图 5. Yamazaki 等 2022 原文 Figure 5,展示 DCSNN 从输入图像、DoG filter、卷积/池化窗口到全局池化和决策层的结构。原文为 CC BY 4.0 开放获取。
Figure 6 是用于 SLAM 的 SNN 架构。这里 SNN 不只是分类器,而是可以嵌入机器人感知、位置估计和导航回路。
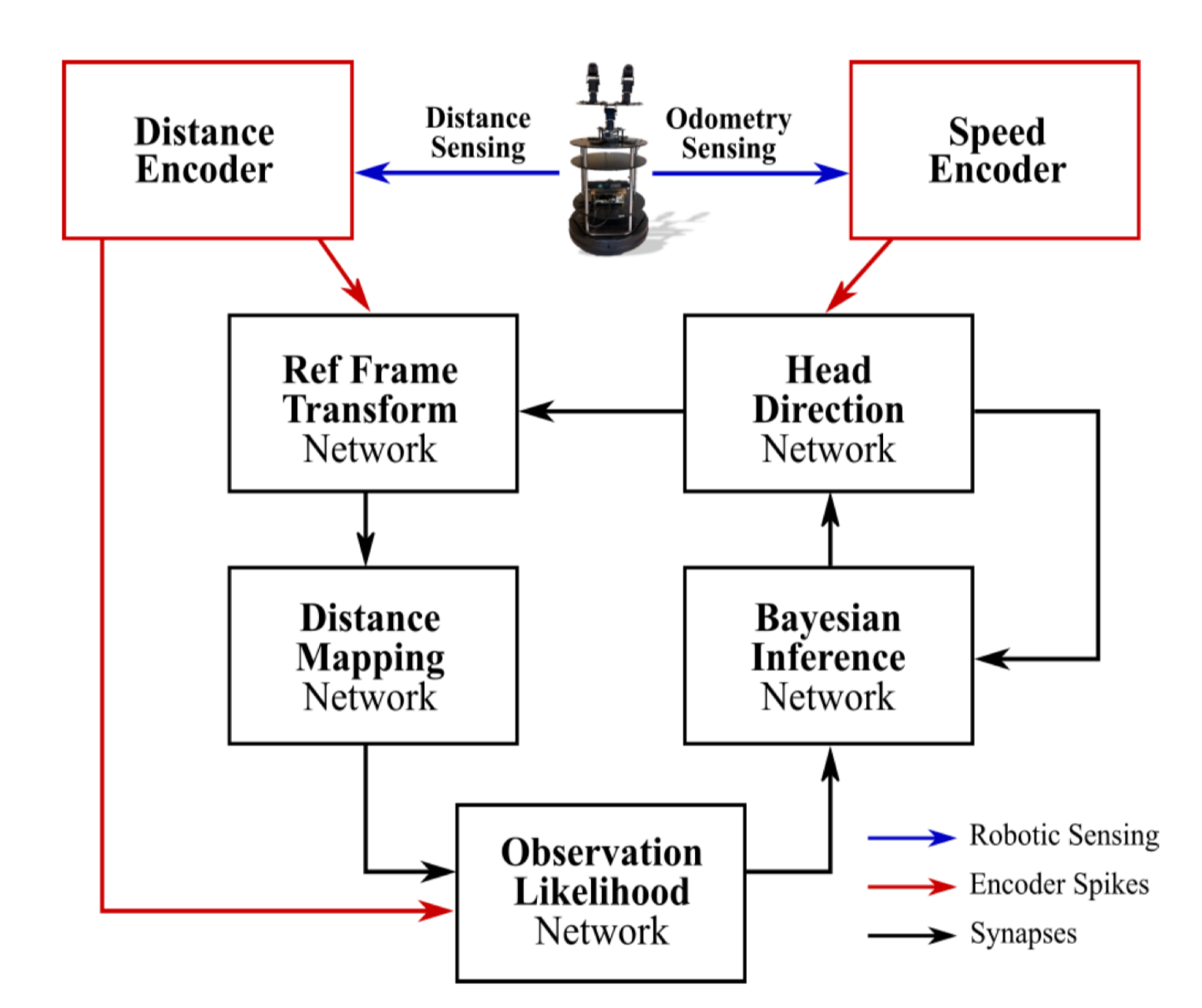
图 6. Yamazaki 等 2022 原文 Figure 6,展示距离编码、速度编码、head direction network、Bayesian inference network 和 observation likelihood network 在 SLAM 回路中的连接。原文为 CC BY 4.0 开放获取。
Table 1 的核心是三列对照:biological NNs 用 spike 和 synaptic plasticity;ANNs 用 scalar 和 BP;SNNs 用 spike,但学习可以是 plasticity 或 BP。
Table 2 汇总 SNN 在视觉任务里的应用,包括分类、目标检测、分割、跟踪、光流估计等。
Table 3 汇总 SNN 在机器人里的应用,包括导航、SLAM、运动控制、强化学习和 neuromorphic hardware。
Table 4 汇总 SNN 软件框架,例如 NEST、Brian、BindsNET、Nengo、CARLsim 等。选择框架时要看目标:生物模拟、大规模仿真、深度学习接口还是硬件部署。
3. 公式逐条解释
3.1 膜电位和动作电位
式 (1):Goldman-Hodgkin-Katz 方程
式 (1) 是 Goldman-Hodgkin-Katz membrane potential equation,用来估计细胞膜内外的电位差。$v_m$ 是膜电位,$R$ 是气体常数,$T$ 是绝对温度,$F$ 是 Faraday 常数。$P_K$、$P_{\mathrm{Na}}$、$P_{\mathrm{Cl}}$ 是膜对不同离子的通透性。
分子表示“推动膜电位向外侧浓度方向变化”的离子项,分母表示内侧浓度项。注意 $\mathrm{Cl}^-$ 是负离子,所以它的 inside/outside 位置和阳离子相反。这个公式说明:膜电位不是单一离子决定的,而是多个离子浓度和膜通透性的加权结果。
式 (2):静息膜电位
式 (2) 是把典型静息状态下的离子浓度和相对通透性代入式 (1)。论文给出的静息通透性比例是 $P_K:P_{\mathrm{Na}}:P_{\mathrm{Cl}}=1:0.04:0.45$。结果约为 $-70.15\ \mathrm{mV}$,说明细胞内相对于细胞外更负。
这个结果是理解 spike 的基础:神经元平时不是 0 mV,而是处在负的静息状态。后续模型里的 $E_L$、$E_m$、$v_{\mathrm{reset}}$ 都是在模拟这种回落到静息态的趋势。
式 (3):动作电位峰值
式 (3) 模拟动作电位峰值。动作电位发生时,钠通道开放,$\mathrm{Na}^+$ 通透性显著升高。论文用峰值时的近似比例 $P_K:P_{\mathrm{Na}}:P_{\mathrm{Cl}}=1:12:0.45$,得到约 $38.43\ \mathrm{mV}$。
这解释了为什么 spike 是一个快速上冲再回落的事件:钠通道开放让膜电位向正值冲上去,随后钾通道和漏电流把膜电位拉回来。
3.2 ANN 的 firing-rate 写法
式 (4):ANN 层的向量形式
式 (4) 是标准 ANN 层。$\mathbf{u}\in\mathbb{R}^{N_{\mathrm{pre}}}$ 是上一层神经元的 firing rate 或激活值,$\mathbf{r}\in\mathbb{R}^{N_{\mathrm{post}}}$ 是当前层输出。$W$ 是权重矩阵,$\mathbf{b}$ 是 bias,$f(\cdot)$ 是非线性激活函数。
ANN 和 SNN 的关键区别就在这里:ANN 用连续值 $\mathbf{r}$ 表达神经元状态,而 SNN 通常用 spike train 表达输出。ANN 的反向传播直接依赖连续可导的 $f$;SNN 的 spike 是离散事件,因此训练更难。
3.3 Hodgkin-Huxley 模型
式 (5):膜电容方程
式 (5) 把细胞膜看成电容。$C_m$ 是膜电容,$v_m$ 是膜电位。左边是膜电位变化需要的电荷变化;右边是离子电流 $I_{\mathrm{ion}}$ 和突触输入电流 $I_{\mathrm{syn}}$。
直观理解:电流进入或离开膜电容,会改变膜电位。HH 模型的目标就是细致描述这些离子电流如何产生动作电位。
式 (6):离子电流
式 (6) 把离子电流拆成三部分:钾电流、钠电流、漏电流。$G_K$、$G_{\mathrm{Na}}$、$G_L$ 是最大电导;$E_K$、$E_{\mathrm{Na}}$、$E_L$ 是反转电位。
$n$ 是钾通道激活变量,$m$ 是钠通道激活变量,$h$ 是钠通道失活变量。$n^4$、$m^3h$ 表示通道打开概率的非线性组合。HH 模型生物真实性强,就强在它不是简单设一个 threshold,而是显式模拟离子通道状态。
式 (7):门控变量动力学
式 (7) 描述门控变量 $g$ 的变化,$g$ 可以是 $n$、$m$ 或 $h$。$\alpha_g(v_m)$ 是从关闭到打开的速率,$\beta_g(v_m)$ 是从打开到关闭的速率。
第一项 $\alpha_g(v_m)(1-g)$ 表示还没打开的比例中,有一部分会打开。第二项 $\beta_g(v_m)g$ 表示已经打开的比例中,有一部分会关闭。这个公式让通道状态随着膜电位动态变化。
式 (8):HH 门控速率函数
式 (8) 给出 $m$、$h$、$n$ 的电压依赖速率。$m$ 控制钠通道激活,$h$ 控制钠通道失活,$n$ 控制钾通道激活。
这些函数的意义是:膜电位越接近某些范围,通道打开或关闭的速度就越快。HH 模型因此能自然产生快速上升、峰值、复极化和后超极化等动作电位形态。
3.4 LIF 模型
式 (9):Leaky Integrate-and-Fire
式 (9) 是 LIF 模型。第一行描述膜电位积分和泄漏。$-G_L(v_m-E_L)$ 是 leak term,它把膜电位拉回漏电位 $E_L$;$I_{\mathrm{syn}}$ 是突触输入。
第二行是 spike 规则:当膜电位超过阈值 $v_\theta$,神经元发放 spike,然后膜电位重置到 $v_{\mathrm{reset}}$。LIF 的优点是便宜、简单、适合大规模 SNN;缺点是动作电位形态是人为规则,不像 HH 那样由离子通道自然产生。
式 (10):恒定输入下的膜电位解
式 (10) 是在 $I_{\mathrm{syn}}(t)=I$ 且 $v_{\mathrm{reset}}=0$ 时,LIF 的解析解。$R_m$ 是膜电阻,$\tau_m=R_mC_m$ 是膜时间常数。
这个式子说明:输入电流恒定时,膜电位不会线性无限上升,而是指数式接近 $R_mI$。$\tau_m$ 越大,膜电位上升越慢。
式 (11):第一次发放时间
式 (11) 是把式 (10) 设为阈值 $v_\theta$ 后解出来的第一次 spike 时间。$R_mI$ 越大,膜电位越快到阈值,$t^{(1)}$ 越短。
如果 $R_mI\le v_\theta$,分母不再给出有效发放时间,表示输入太弱,膜电位到不了阈值。
式 (12):稳态发放率
式 (12) 把一次发放周期写成“积分到阈值的时间 + refractory period”。取倒数就是 firing rate。
这个式子很重要,因为它把 SNN 的 spike dynamics 和 ANN 的 activation function 联系起来:输入越强,发放率越高;在某些简化条件下,它近似 ReLU。因此 ANN-to-SNN conversion 经常利用这个关系。
3.5 Izhikevich 模型
式 (13):膜电位方程
式 (13) 是 Izhikevich 模型的膜电位方程。$k(v_m-E_L)(v_m-v_t)$ 是二次非线性项,用来产生快速上升的 spike 动力学。$u$ 是恢复变量,代表钾电流激活和钠电流失活带来的负反馈。
这个模型比 LIF 更能表现不同神经元放电模式,同时比 HH 便宜很多。
式 (14):恢复变量方程
式 (14) 描述恢复变量 $u$ 如何跟随膜电位变化。$a$ 控制恢复速度,$b$ 控制膜电位对恢复变量的影响强度。
当膜电位升高时,$u$ 也会被推高;$u$ 又在式 (13) 中以 $-u$ 抑制膜电位。这形成一个恢复机制,让神经元不只是一直兴奋,还能复位和产生复杂放电模式。
式 (15):Izhikevich reset
式 (15) 是 spike 后的重置规则。$v_m$ 被设为 $c$,恢复变量 $u$ 增加 $d$。
这个 reset 让模型可以产生 regular spiking、bursting、fast spiking 等多种模式。不同参数组合对应不同皮层神经元放电类型。
3.6 AdEx 模型
式 (16):AdEx 膜电位方程
式 (16) 是 Adaptive Exponential Integrate-and-Fire 模型。第一项是 leak,第二项是指数项,用来模拟接近阈值时钠通道激活导致的快速上升。$w$ 是适应电流,会抑制膜电位继续升高。
$\Delta_T$ 控制 spike onset 的陡峭程度。$\Delta_T$ 越小,模型越接近硬阈值的 LIF。
式 (17):AdEx 适应变量
式 (17) 描述适应变量 $w$。$\tau_w$ 是适应时间常数,$a$ 控制膜电位对适应电流的影响。
膜电位升高时,$w$ 增强;而 $w$ 在式 (16) 里以 $-w$ 出现,因此它会抑制持续兴奋。这能模拟 spike-frequency adaptation。
式 (18):AdEx reset
式 (18) 是 AdEx 的 spike 后 reset。膜电位回到 $v_{\mathrm{reset}}$,适应变量增加 $b$。
$b$ 越大,每次 spike 后适应抑制越强,后续发放越慢。这让模型可以表现频率适应和 burst 后疲劳。
3.7 突触模型
式 (19):单指数突触动力学
式 (19) 假设 spike 到达后突触响应瞬间上升,然后按时间常数 $\tau_d$ 指数衰减。$t_k$ 是第 $k$ 次 spike 的时间。
$s_{\mathrm{syn}}(t)$ 是所有历史 spike 留下的突触痕迹之和。这个模型适合表达“一个 spike 的影响不是瞬间消失,而是逐渐衰减”。
式 (20):单指数模型的微分形式
式 (20) 是式 (19) 的微分方程形式。第一项表示突触状态自然衰减;第二项表示每次 spike 到达时,用 Dirac delta 给系统一次瞬时输入。
这类写法适合仿真,因为只要更新一个状态变量 $s_{\mathrm{syn}}$,不必每次都显式保存全部历史 spike。
式 (21):双指数突触模型
式 (21) 同时描述 rise 和 decay。$\tau_r$ 是上升时间常数,$\tau_d$ 是衰减时间常数。两个指数相减后,响应会先上升再下降,更接近真实 PSC/PSP。
$A$ 是归一化常数,用来控制峰值尺度。单指数只有衰减,不适合描述突触响应的上升阶段;双指数更真实,但计算稍复杂。
式 (22):双指数模型的状态方程
式 (22) 用两个状态变量实现双指数响应。$h$ 是辅助变量,负责上升过程;$s_{\mathrm{syn}}$ 负责最终突触状态。
如果 $\tau_r$ 和 $\tau_d$ 合并到特定形式,就会得到常见的 alpha function。这个模型在生物神经元仿真里比单指数更常用。
式 (23):突触输入电流
式 (23) 把 presynaptic synaptic kinetics 转成 postsynaptic input current。 是前突触神经元的突触状态向量,$W$ 是突触权重矩阵, 是后突触输入电流。
这和 ANN 的 $W\mathbf{u}$ 很像,但 来自 spike history,而不是静态激活值。
3.8 Spike-based backpropagation
式 (24):SuperSpike 损失
式 (24) 用平滑后的 spike train 差异定义损失。$s(t)$ 是输出 spike train,$\hat{s}(t)$ 是目标 spike train,$\alpha$ 是平滑卷积核,$*$ 表示时间卷积。
直接比较 spike train 很困难,因为 spike 是 delta 事件;用 $\alpha$ 平滑后,可以得到连续误差信号,便于优化。
式 (25):用 surrogate function 近似 spike 导数
式 (25) 是 SNN 训练的关键。真正的 spike function 不可导,所以用连续函数 $\sigma(v_m)$ 近似。论文使用 fast sigmoid:
这个思想就是 surrogate gradient:前向仍然发 spike,反向传播时用可导近似替代不可导的 spike 导数。
式 (26):SuperSpike 梯度
式 (26) 可以拆成两部分。第一部分 $\alpha*(s-\hat{s})$ 是误差信号;第二部分是 eligibility trace,表示这个突触在当前误差里“有没有资格负责”。
$s_{\mathrm{pre}}$ 是 presynaptic spike train,$\epsilon$ 是平滑核。这个公式把全局误差和局部突触活动结合起来,是 spike-based backpropagation 的核心。
式 (27):SLAYER 梯度
式 (27) 来自 SLAYER。$\rho(t)$ 是 spike escape rate 相关的概率密度,$e$ 是反向传播得到的误差信号,$\odot$ 表示时间上的 element-wise correlation。
SLAYER 的重点是把误差信用分配到时间上,解决 spike 事件对未来状态产生延迟影响的问题。
3.9 STDP 及其变体
式 (28):标准 STDP
式 (28) 是 spike-time-dependent plasticity。若 presynaptic spike 早于 postsynaptic spike,突触增强;若顺序相反,突触减弱。
$\tau_+$ 和 $\tau_-$ 控制时间窗口。两个 spike 越接近,权重变化越大;时间差越远,影响指数衰减。这个规则体现 Hebbian learning 的时间版本:先来并导致后发的连接会被增强。
式 (29):权重依赖的 STDP 幅度
式 (29) 让 STDP 的幅度依赖当前权重。$w$ 太大时,增强幅度会变小,减弱幅度会变大;$w$ 太小时则相反。
这样做是为了稳定学习,避免式 (28) 让权重无限增加或无限减少。$w_{\mathrm{init}}$ 可以理解为权重的参考点。
式 (30):trace 形式的 STDP 权重更新
式 (30) 用 spike trace 避免保存所有 spike 时间。$x_{\mathrm{pre}}$ 是 presynaptic trace,$x_{\mathrm{post}}$ 是 postsynaptic trace。$\delta_{\mathrm{post}}$ 表示 post spike 到来,$\delta_{\mathrm{pre}}$ 表示 pre spike 到来。
当 post spike 到来时,看 pre trace 有多强,决定增强多少;当 pre spike 到来时,看 post trace 有多强,决定减弱多少。这就是 STDP 的在线实现。
式 (31):pre/post spike trace
式 (31) 说明 spike trace 会指数衰减,并在 spike 到来时增加。$\tau_+$ 和 $\tau_-$ 控制记忆时间。
这比显式存储所有 spike timing 更适合硬件和在线学习。论文也指出,这种 trace 可以和 NMDA receptor、Ca$^{2+}$ influx 等生物过程联系起来。
式 (32):anti-Hebbian STDP
式 (32) 是 anti-Hebbian STDP,方向和标准 STDP 相反。pre 早于 post 时不增强,反而倾向减弱;post 早于 pre 时倾向增强。
这种规则用于描述某些不遵循标准 Hebbian 顺序的神经系统,也可用于特定网络结构里的反向或反馈学习。
式 (33):probabilistic STDP
式 (33) 是 probabilistic STDP 的简化形式。LTP 的幅度随当前权重 $w$ 增大而减小,避免权重过度增强;LTD 使用固定负更新。
它的目的也是稳定学习,让 STDP 不至于把权重推到不可控范围。
式 (34):reward-modulated STDP 权重更新
式 (34) 是 R-STDP。$r(t)$ 是 reward,$z_{i,j}(t)$ 是 eligibility trace。$\eta$ 是学习率。
STDP 本身只看 pre/post spike 的时间关系;R-STDP 加入 reward,把局部突触资格和全局奖励结合起来。这样 SNN 可以用于强化学习。
式 (35):eligibility trace
式 (35) 说明 eligibility trace 会衰减,并由当前 STDP 事件补充。它记录“这个突触刚才有没有发生值得学习的时序关系”。
reward 往往是延迟到来的。eligibility trace 的作用就是保留短期记忆,让稍后出现的 reward 能分配给之前相关的突触事件。
式 (36):PES 学习规则
式 (36) 是 prescribed error sensitivity。$e(t)$ 是外部误差信号,$a$ 是神经元 rate activity,$\eta$ 是学习率。
它适合 online adaptive control。和 STDP 不同,PES 是监督式误差驱动:有明确误差信号时,权重按照误差方向调整。
式 (37):intrinsic plasticity 调节量
式 (37) 根据 inter-spike interval, ISI 调节神经元自身兴奋性。$\Delta t_{\mathrm{ISI}}$ 太小表示神经元发得太频繁,需要降低兴奋性;$\Delta t_{\mathrm{ISI}}$ 太大表示发得太少,需要提高兴奋性。
这不是突触学习,而是神经元自身阈值或偏置的调节。它用于维持合适的 firing range,避免神经元沉默或饱和。
式 (38):intrinsic bias 更新
式 (38) 把式 (37) 的调节量加到神经元 bias 或 excitability 参数上。$b_{\max}$ 控制最大调节尺度。
如果 spike 过密,$\phi$ 为负,$b$ 降低;如果 spike 太稀疏,$\phi$ 为正,$b$ 升高。这是一种 homeostatic control。
3.10 Spike encoding
式 (39):时间窗内 spike count
式 (39) 统计时间窗 $[0,T]$ 内的 spike 数量。$t_k$ 是第 $k$ 个 spike 的时间,Dirac delta 在 spike 发生时给出一个单位事件。
这个公式对应 rate encoding:不关心每个 spike 的精确时间,只关心一段时间内出现了多少个 spike。
式 (40):firing rate
式 (40) 把 spike count 除以时间窗长度,得到 firing rate。$T$ 越长,估计越平滑;$T$ 越短,时间分辨率越高但噪声更大。
rate encoding 容易和 ANN 的连续激活值对接,但会损失精细 spike timing 信息。
式 (41):Poisson spike 发生概率
式 (41) 来自 Poisson process。$\lambda$ 是强度或 firing rate,$\Delta t$ 是很短的时间步。若 $\Delta t$ 足够小,发生一次 spike 的概率近似为 $\lambda\Delta t$。
这个公式常用于把连续像素值或连续输入转换成随机 spike train。输入越强,$\lambda$ 越大,单位时间内更容易发 spike。
式 (42):根据随机数生成 spike
式 (42) 是 Poisson rate encoding 的实际采样规则。每个时间步生成一个均匀随机数 $\xi$。如果 $\xi<r\Delta t$,就产生 spike;否则不产生。
这样就把连续 firing rate $r$ 转成二值 spike sequence。缺点是随机性会带来噪声;优点是实现简单,和 rate-based ANN 转 SNN 比较兼容。
4. 训练方法怎么选
这篇论文把 SNN 训练分成几类:
- Spike-based backpropagation:性能潜力高,但要处理 spike 不可导问题,通常需要 surrogate gradient。
- STDP 系列:更生物可信,适合无监督、在线、本地学习,但大规模复杂任务性能通常不如监督训练。
- Reward-modulated STDP:把 reward 加进局部突触可塑性,适合强化学习和机器人。
- PES:适合带外部误差信号的在线控制。
- ANN-to-SNN conversion:目前很多高性能视觉 SNN 依赖这条路线,优点是能继承成熟 ANN 架构,缺点是可能需要较长时间窗才能接近 ANN 精度。
一个实用判断:
| 目标 | 更合适的方法 |
|---|---|
| 追求 ImageNet/CNN 性能 | ANN-to-SNN conversion 或 surrogate gradient |
| 追求生物合理性 | STDP、R-STDP、intrinsic plasticity |
| 追求机器人在线控制 | R-STDP、PES、NEF 相关方法 |
| 追求低功耗部署 | SNN + neuromorphic hardware |
| 处理事件相机数据 | 原生 SNN 或 event-driven SNN |
5. 应用部分怎么理解
论文的应用部分主要讲两大类:computer vision 和 robotics。
在 computer vision 中,SNN 的优势来自两点。第一,视觉任务可以用 event camera 产生的事件流作为天然 spike 输入;第二,传统 CNN 可以转成 SNN,在神经形态硬件上减少能耗。论文列举了图像分类、目标检测、语义分割、医学图像、目标跟踪、光流估计等方向。
在 robotics 中,SNN 的价值更明显,因为机器人需要实时响应、低功耗、在线学习和传感器事件流。论文列举了 obstacle avoidance、SLAM、navigation、UAV control、mapless navigation 等任务。
但应用部分也暴露出限制:很多 SNN 工作还停留在 MNIST、N-MNIST、N-Caltech101 这类相对简单数据集;复杂视觉任务上,SNN 往往仍依赖 ANN conversion 或混合 ANN-SNN 架构。
6. 这篇综述的价值和局限
这篇论文的价值在于,它把 SNN 的基础组件按工程链条排好了:
如果刚开始学 SNN,最应该抓住四个问题:
- 信息怎么表示:rate code 还是 temporal code?
- 神经元怎么发放:LIF、Izhikevich、AdEx 还是 HH?
- 突触怎么积分历史 spike:单指数还是双指数?
- 权重怎么学:STDP、surrogate gradient、R-STDP 还是 ANN conversion?
局限也很清楚:
- 这是 2022 年综述,后来的 transformer-SNN、large-scale surrogate training、直接训练深层 SNN、LLM 时代的 neuromorphic 讨论没有覆盖。
- 公式多来自经典模型,论文主要是整理,不是给出统一理论。
- 应用总结以视觉和机器人为主,对医学信号、脑电、SEEG、神经数据建模涉及较少。
- 对能耗优势的讨论偏概念,具体能耗要依赖硬件、编码方式、时间步长度和稀疏程度。
7. 最后总结
SNN 的核心不是“把 ANN 变得更像大脑”这么简单,而是换了一套计算单位:
这带来三个直接后果:
- 表达更稀疏:没有 spike 时可以不计算,适合低功耗硬件。
- 时间更重要:信息可以藏在 spike timing 里,而不只是 firing rate 里。
- 训练更困难:spike 不可导,必须用 STDP、surrogate gradient、R-STDP 或 ANN-to-SNN conversion 绕开。
如果只记一句话:SNN 是把神经网络从“连续值矩阵计算”推进到“事件驱动的动态系统计算”;它的优势在稀疏、时序和能耗,难点在训练、精度和工程生态。
参考文献
[1] Yamazaki, K.; Vo-Ho, V.-K.; Bulsara, D.; Le, N. Spiking Neural Networks and Their Applications: A Review. Brain Sciences 2022, 12(7), 863. DOI: https://doi.org/10.3390/brainsci12070863