在用python requests爬取ncbi数据库时候,会有个苦恼的地方,就是在通过ncbi数据库检索到蛋白后,地址栏给出的地址是隐藏的,即使你通过该出的该地址也无法打开对应的地址网页,也就无法正常爬取网页信息,如下图所示,
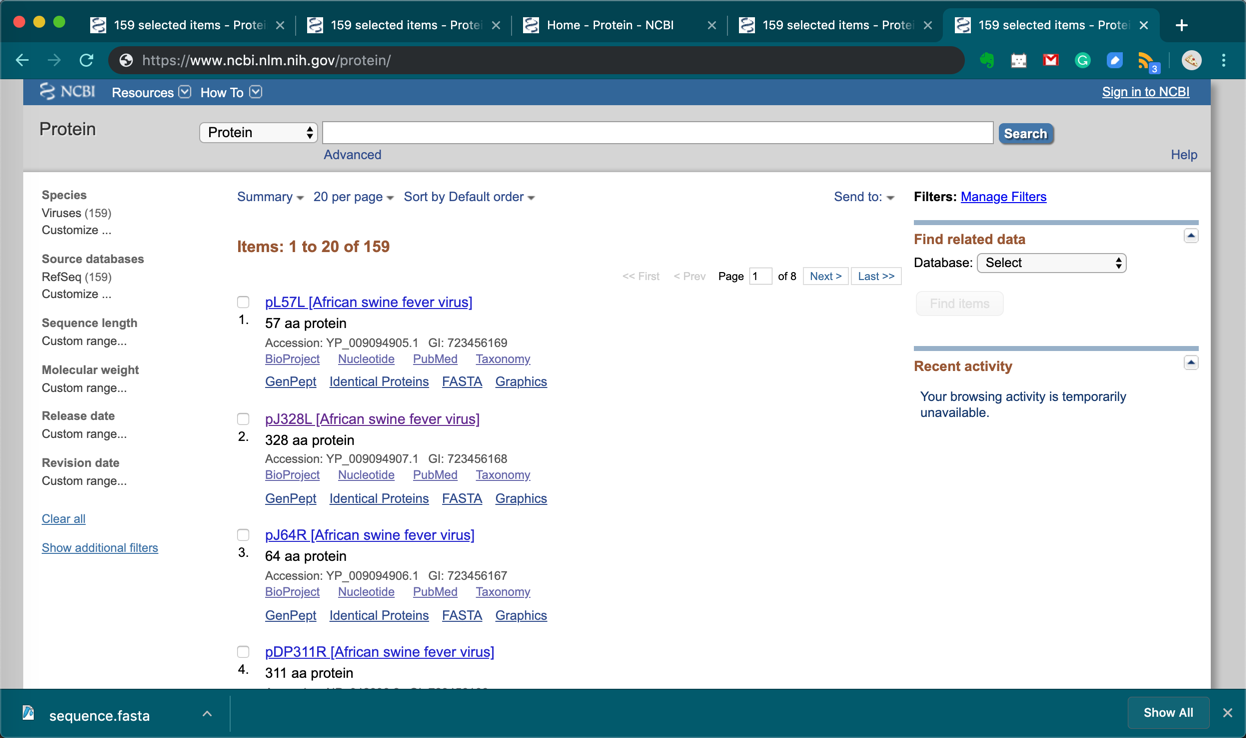
可以看到即使我更改Summary为Fasta,并且将20 per page更改为200 per page,也无法看到完整的地址信息,
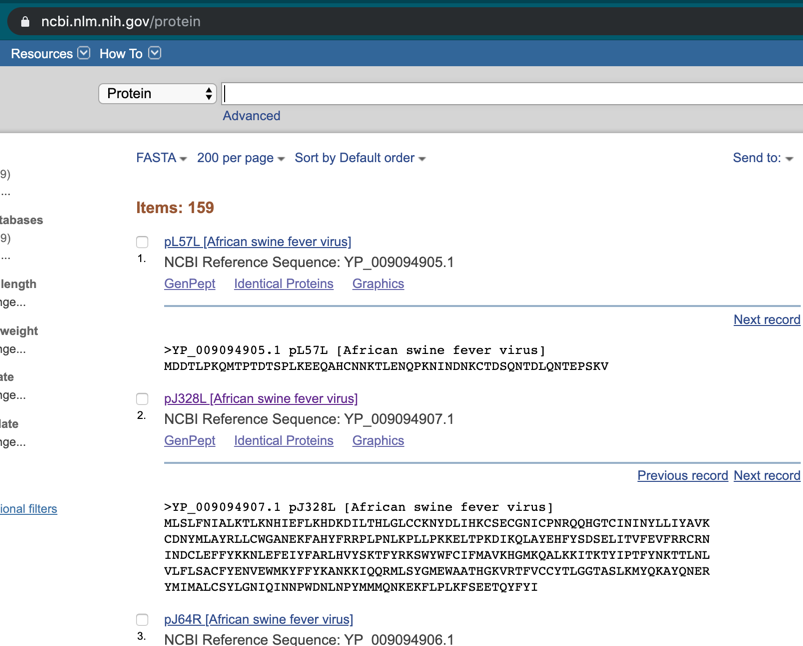
下面我来介绍如何将完整的地址找到,
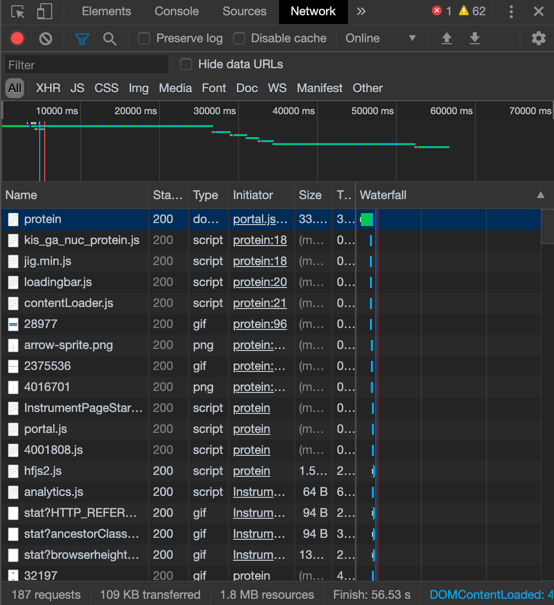
首先inspect,并查看Network 选项,要注意重新刷新,比如说将20 per page更改为200 per page,Network才会刷新记录,结果如图:
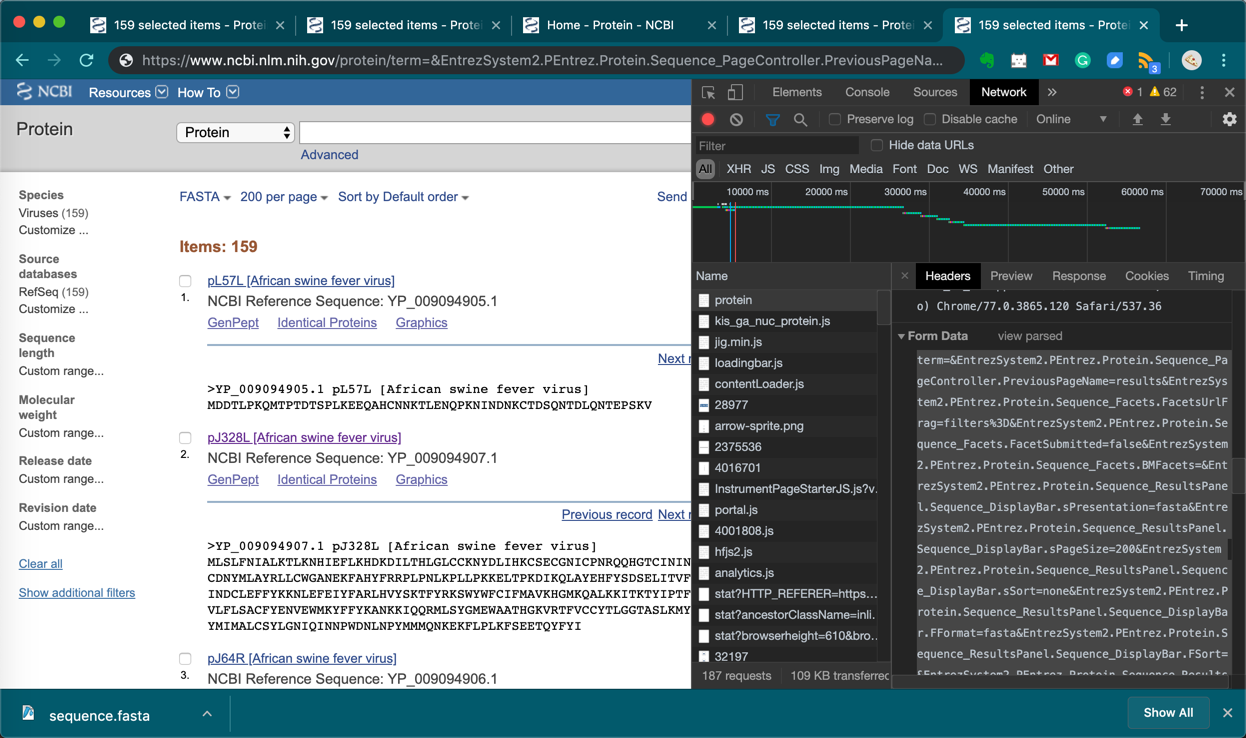
选择光标处的 protein,在Headers 菜单中寻找到这个菜单栏,如图,
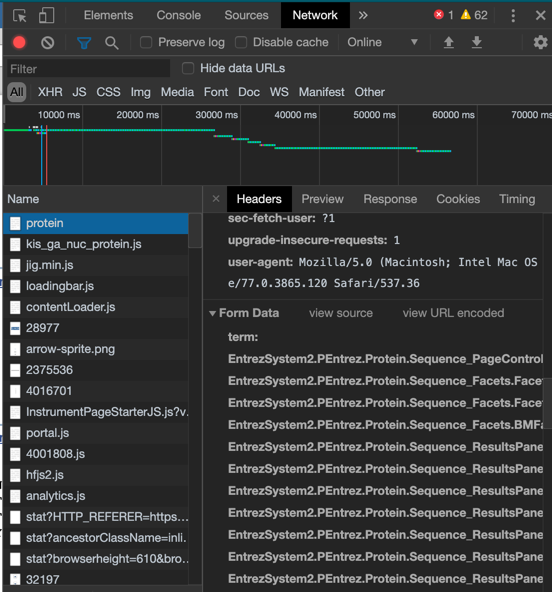
在该栏目中选择view source,并赋term=...地址,粘贴到地址栏中,如图所示,
可以尽情的爬了!祝爬虫愉快!