本文为学习鱼c论坛相关课程视频笔记,观看原视频访问这里。
Requests,与BeautifulSoup模块的安装
pip install requests
pip install bs4
解析网页内容使用BeautifulSoup模块,将复杂的网页结构转化为书籍目录的形式。
代码示例
import requests
import bs4
res = requests.get("http://movie.douban.com/top250")
soup = bs4.BeautifulSoup(res.text, "html.parser")
targets = soup.find_all("div", class_="hd") # 这里网页中class与python class重名,用class_代替
for each in targets:
print(each.a.span.text) #不加text则带着html代码一起打印
检查网页HTML代码,如下图:
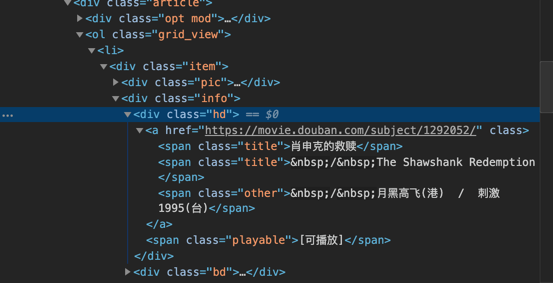
电影标题位于<div class="hd">...</div>标签中,从属关系如下:
div —> a —> span
所以先调用find_all(),找到所有class="hd"的div标签,然后即可按照从属关系取出想要的电影名信息。
值得注意的是,这我想爬取的是第一个span内的名字,如果我想所有名字代码如下:
print(each.a.text)
如果我想指向爬取第二个span内的名字,代码如下:
print(each.a.span.find_next_sibling().text)
下面是完成的爬取代码,方便学习:
import requests
import bs4
import re
def open_url(url):
# 使用代理
# proxies = {"http": "127.0.0.1:1080", "https": "127.0.0.1:1080"}
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.98 Safari/537.36'}
# res = requests.get(url, headers=headers, proxies=proxies)
res = requests.get(url, headers=headers)
return res
def find_movies(res):
soup = bs4.BeautifulSoup(res.text, 'html.parser')
# 电影名
movies = []
targets = soup.find_all("div", class_="hd")
for each in targets:
movies.append(each.a.span.text)
# 评分
ranks = []
targets = soup.find_all("span", class_="rating_num")
for each in targets:
ranks.append(' 评分:%s ' % each.text)
# 资料
messages = []
targets = soup.find_all("div", class_="bd")
for each in targets:
try:
messages.append(each.p.text.split('\n')[1].strip() + each.p.text.split('\n')[2].strip())
except:
continue
result = []
length = len(movies)
for i in range(length):
result.append(movies[i] + ranks[i] + messages[i] + '\n')
return result
# 找出一共有多少个页面
def find_depth(res):
soup = bs4.BeautifulSoup(res.text, 'html.parser')
depth = soup.find('span', class_='next').previous_sibling.previous_sibling.text
return int(depth)
def main():
host = "https://movie.douban.com/top250"
res = open_url(host)
depth = find_depth(res)
result = []
for i in range(depth):
url = host + '/?start=' + str(25 * i)
res = open_url(url)
result.extend(find_movies(res))
with open("豆瓣TOP250电影.txt", "w", encoding="utf-8") as f:
for each in result:
f.write(each)
if __name__ == "__main__":
main()